At the beginning of the COVID-19 outbreak, there was a great deal of debate about how to quickly and reliably detect patients who have been infected by the SARS-CoV-2 virus. By far, the most commonly used approach is the Reverse Transcription Polymerase Chain Reaction (PCR) method. Studies have shown that a sensitivity of only about 89% can be achieved with such tests. As such, it becomes necessary for clinicians to analyse other sources such as Chest X-Rays in some cases. While only up to 59% of infected patients manifest abnormal Chest X-Rays, it has been shown to be a useful tool for excluding alternative conditions like lobar collapse, pneumothorax, or pleural effusion [Chan et al.]. In addition, in cases where PCR results are inconclusive initially, the Chest X-Ray is an important deciding factor in diagnosing patients who show clinical and epidemiological features comparable to COVID19.
One advantage of using Chest X-Rays as a source is that image-based Machine Learning can be applied to them as part of a decision support tool for clinicians. The problem however is a dearth of X-Rays from positive confirmed cases, as opposed to several thousand normal X-Rays and X-Rays from non-related conditions. This data skew is very typical among Machine learning problems and one solution is to generate artificial data to augment the minor class (in this case, X-Rays for positive infected cases). There are many types of data generators. We make use of a fairly recent and promising technique known as the Generative Adversarial Networks (GAN), which was famously used to beat a world class Go player [Chen et al.] as well as to create convincing but fake pictures of celebrities [Karras et al.].
Conceptually, any two dimensional image can be ‘flattened’ into a one dimensional vector. For the same type of image eg. dog images, we expect similarities between the vectors derived from different dogs. Conversely, large differences are highly likely between an image of a dog and an image of a man. We can further generalise that dog images can be represented by a statistical distribution, very different from the distribution for a man. This is where GANs become useful – A GAN is made up of a Generator (G) and a Discriminator (D). G is useful for creating a function that approximates the statistical distribution of the target image type. Since the true distribution of that type is usually unknown and since the image differences are usually subtle and problem specific, a ‘blackbox’ Discriminator D is used for the task at hand rather than a predetermined function. The performance of D can then be incrementally improved using the strategy outlined as follows – The modules G and D work at cross purposes – On one hand, D is being fed both authentic and false data and trained to distinguish between them. On the other hand, G is trained to falsify images that are similar enough to the original in order to ‘fool’ D as part of a concurrent training process. The desired outcome is for G to generate data that is capable of fooling D half the time (similar odds to a coin toss). This will lead to a generator that closely approximates the statistical distribution function for that image type. Once G is properly trained, an arbitrary number of different images can be obtained by feeding G with random vectors (latent vectors).
Progressive GANs (PGANs) belong to a sub-class of GANs. While conventional GANs are fixed in structure in terms of both G and D throughout the training process, PGANs consist of small networks at the beginning which are capable of generating images at a very coarse resolution. As the training progresses, more layers are added to both G and D, akin to growing a crystal. The generated images increase in resolution and grow richer in content as these layers are gradually added. This is illustrated in Figure 1. Training large networks take a long time for the parameters to converge to near-optimal values. By breaking up the problem into bite sizes in this way, the algorithm converges more quickly and easily. Indeed, since early layers are used to define the coarse features within the image (eg. background colour, outline of body), they do not usually change much after stabilising at the earlier training stages. This leaves the algorithm to focus on other layers responsible for the finer features of the image (eg. shapes of the bones). In this way, large PGANs capable of generating high resolution images can be created rather efficiently.

Regarding our problem, we were able to gather Chest X-Rays of COVID infected patients from a public repository. In total, we managed to obtain 130 Posterior-Anterior (PA) Chest X-Rays after discarding unsuitable ones. These images have been reformatted to a resolution of 512 x 512 pixels. Images are generated and recorded throughout the training process and stitched together to form the video shown in Figure 2.
https://www.youtube.com/embed/Fq_EvZGkBCc?feature=oembedFigure 2: This video depicts the images generated from the PGAN as training progresses.
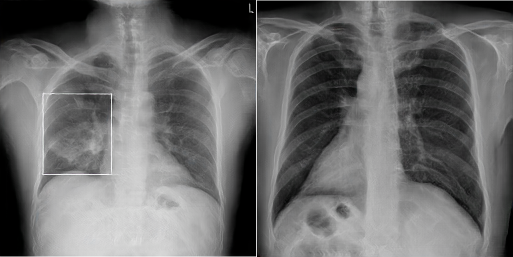
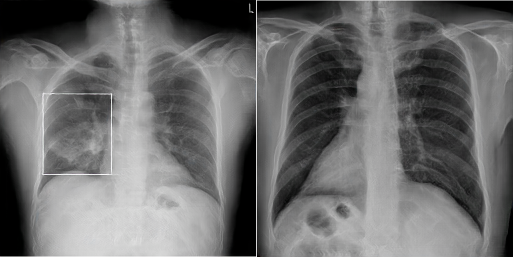
After the PGAN has been fully trained, some sample X-Rays were generated, two of which are shown in Figure 3. Admittedly, the quality of the images generated varies substantially, and an additional manual selection step is necessary to ensure a high level of quality in the images chosen for development.
Manual image selection is not a plausible option if the objective is to harvest images in the hundreds of thousands. Therefore, we are working on different techniques to automate the entire workflow.